
Code&Data Insights
[Deep Learning] Recurrent Neural Networks (RNN) 본문
[Deep Learning] Recurrent Neural Networks (RNN)
paka_corn 2023. 12. 10. 09:24Recurrent Neural Networks (RNN)
: the current output depends on all the previous inputs *SEQUENCE*

Xt = current input
Ht = previous state
W = set of learnable parameters
Comparison between a hidden RNN layer and a linear layer
- Hidden RNN Layer
: the memory that maintains info about past inputs in the sequence
=> The hidden state is updated at each time stop and can capture short-term dependencies within the sequence.
- Linear Layer
: takes input and produces output without considering any temporal dependencies
=> A linear layer treats each time step independently, NOT capture sequential info
=> Lack of maintain memory of past inputs and their influence on the current output
Unfolded RNN
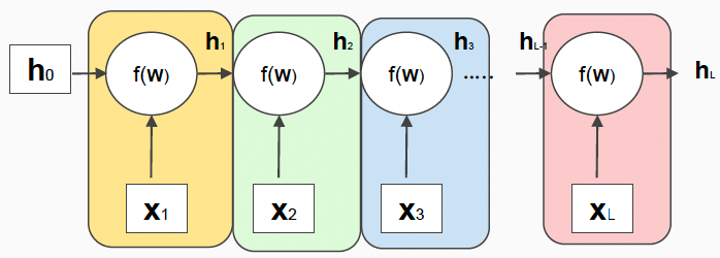

=> Final state hL : L depends on all the inputs
** apply the same neural network f for all the sequence steps (weight sharing)
** RNNs share a full neural network, deep in time-axis
-> can find arbitrary long pattern
Different Types of RNN
(1) a prediction at each time step(many-to-many)
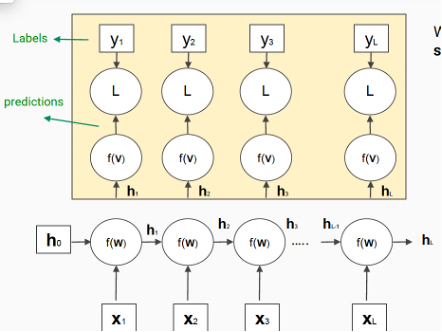
(ex) stock prediction, prediction of next word
- apply a final transformation(linear model) on top of each hidden state
- apply a loss function at each time step(CCE, MSE)
- total loss will eb the sum(or avg) of all the losses at each time step
(2) a single prediction at the end(many-to-one)
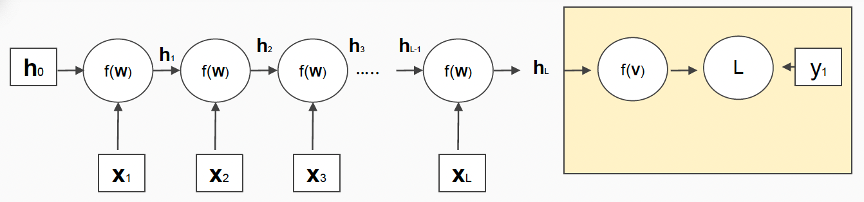
(ex) speaker identification, emotion recognition from text
- apply a final transformation(linear model) on top of the last hidden state
- apply a loss function on top of it
(3) Seq2Seq
: RNN-based encoder + RNN-based decoder
- Encoder : encodes all the L inputs

- Decoder : takes one of many encoded states and generates(one by one) the output elements
=> loss is computed on top of each prediction

(ex) attention mechanism, machine translation, speech recognition
How to Train RNN
- After unfolding it, the RNN becomes a standard computational graph that employs long chains of computations
- Compute the gradient with the backpropagation algorithm ( backpropagation through time )
- With the gradient, we can update the parameters with gradient descent
Vanilla RNN
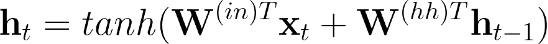
Problem in RNN - Vanishing Gradient
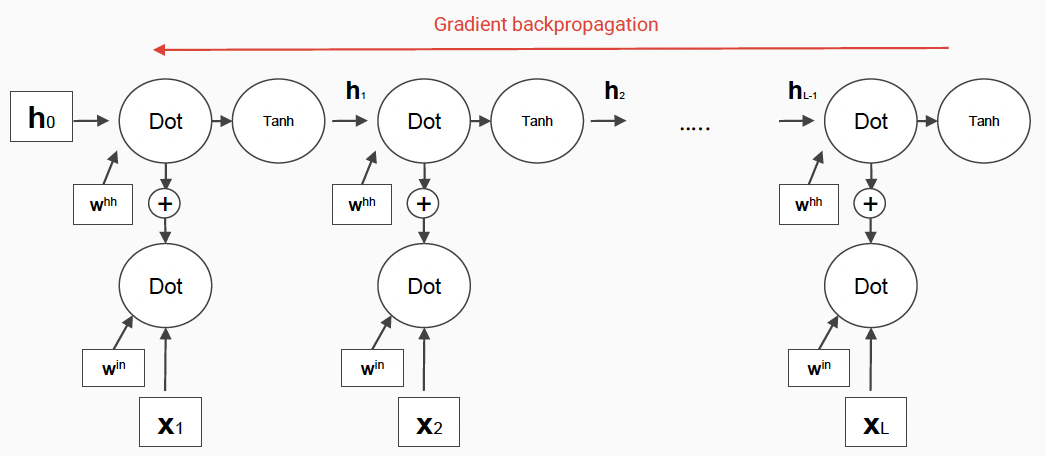
- In RNN, the gradient through a long temporal chain
- Vanishing/ Exploding Gradient
=> The vanishing gradient problem prevents the model to learn long-term dependencies
=> Adding shortcuts across time steps may prevent these problems
Bidirectional RNN
: employ two RNNs running in opposite directions, make a prediction at each time step based on the whole input elements and not only the previous ones.

- combine the forward and the backward state by concatenating them or summing them up
(ex) speech recognition, machine translation, and handwritten recognition
CNNs + RNNs + MLPs
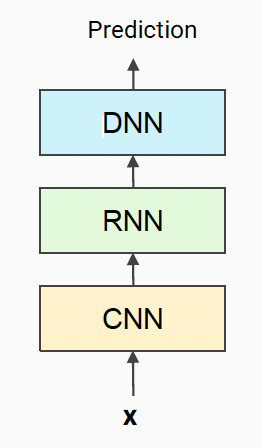
- CNN : learns local contexts
- RNN : learn long-term dependencies
- MLP : performs a final classification



