
Code&Data Insights
[Deep Learning] Advanced Optimization Methods - Momentum | Adaptive Learning Rate | AdaGrad | RMSProp | Adam | Distributed Synchronous SGD 본문
[Deep Learning] Advanced Optimization Methods - Momentum | Adaptive Learning Rate | AdaGrad | RMSProp | Adam | Distributed Synchronous SGD
paka_corn 2023. 11. 2. 03:42Benefits of Advanced optimization methods
- Faster Convergence
- Improved Stability
- Avoiding Local Minima
- Better Generalization
Momentum

: accumulates an exponentially-decaying moving average of the past gradients
- NOT ONLY denpends on learning rate, but ALSO past gradients
(SDG with Batch)
If the previous update vt is very different from the current gradient
=> little update
If previous update vt is similar to the current gradient
=> large update

- θ1 curves much more steeply compared to θ2
=> To slow down the convergence of θ1, we do a little update for θ1
=> and a larger update for θ2
[ Effect of the Momentum ]

- Prevent getting stuck in poor local minima
- Popular and simple approach to speed up and stabilize learning
- It is to dampen the oscillations(진동을 억제) observed with SGD and reach the minimum faster.
- So, It leads to a smaller update that minimizes the jumps over the side of the valley
Adaptive Learning Rate
: Using different learning rate for the each parameters

[ Effect of the Adaptive Learning Rate ]
- Faster Convergence
- Reduced Hyperparameter Tuning
- Enhanced Generalization
- Prevent training from diverging or getting stuck in poor local minima by ensuring that the learning rates are suitable for each parameter and adapt to the changing landscape of the loss function.
AdaGrad
: a method that assigns the learning rate to each parameter automatically
In a real case, we have millions of parameters
-> CANNOT set the learning rate MANUALLY!
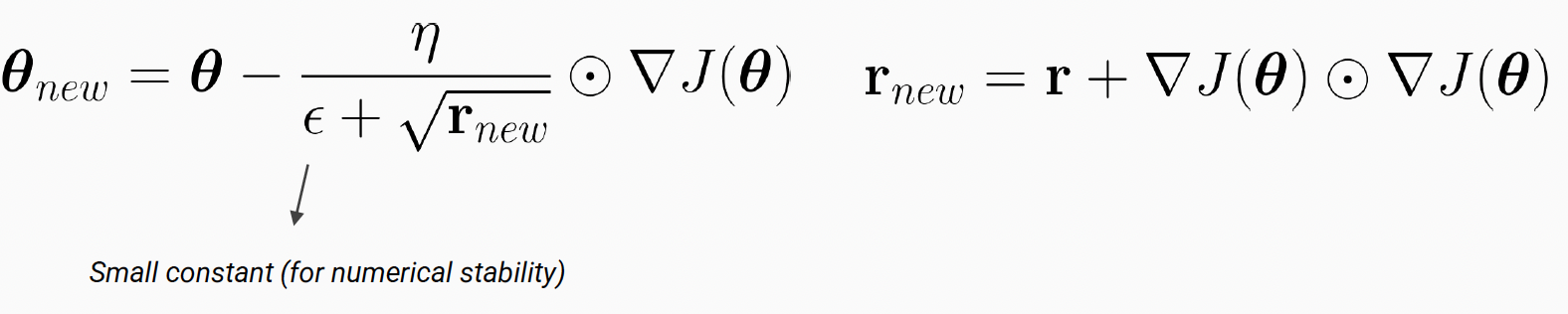
- scale each parameter update using the historical values of the squared gradient magnitude.
- can cause Vanishing | Exploding Gradient Problems
[ Effect of the AdaGrad ]

RMSProp
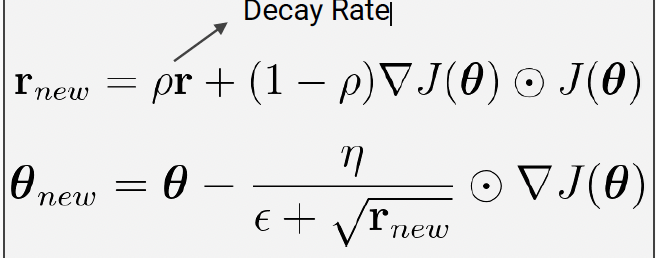
- can avoid vanishing gradient problem (in AdaGrad)
-> mitigates the issue(in AdaGrad) by changing the squared gradient accumulation into an exponential moving average.
- With RMSProp, the direction of the update depends only on the current gradient (ρ1=0), while the step size also depends on the history of the squared gradient.
[ Effect of the RMSProp ]
- NO Vanishing | Exploding Gradient problem
- Adaptive Learning Rates
- Stabilize and speed up the convergence of neural networks
Adam
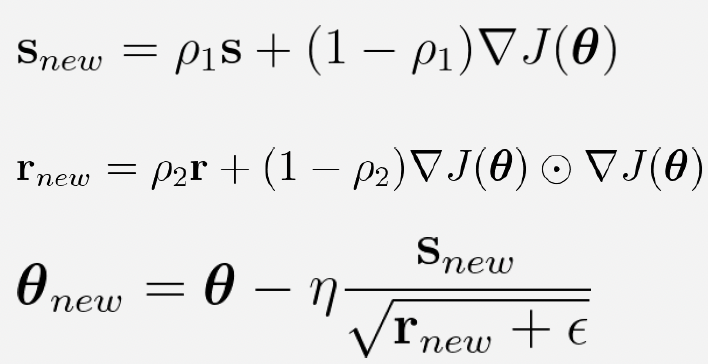
: Momentum + RMSProp
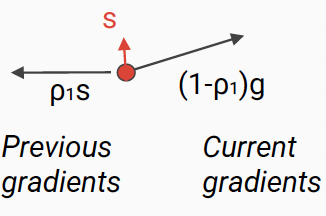
- Similar to momentum, but with exponential weighting
(if the gradient points in the same directions, small if they point if different directions)
- With Adam, both the direction of the update and the step size depends on the past gradients.
( In RMSProp - the direction of the update depends only on the current gradient (ρ1=0), while the step size also depends on the history of the squared gradient )
[ Effect of the Adam ]
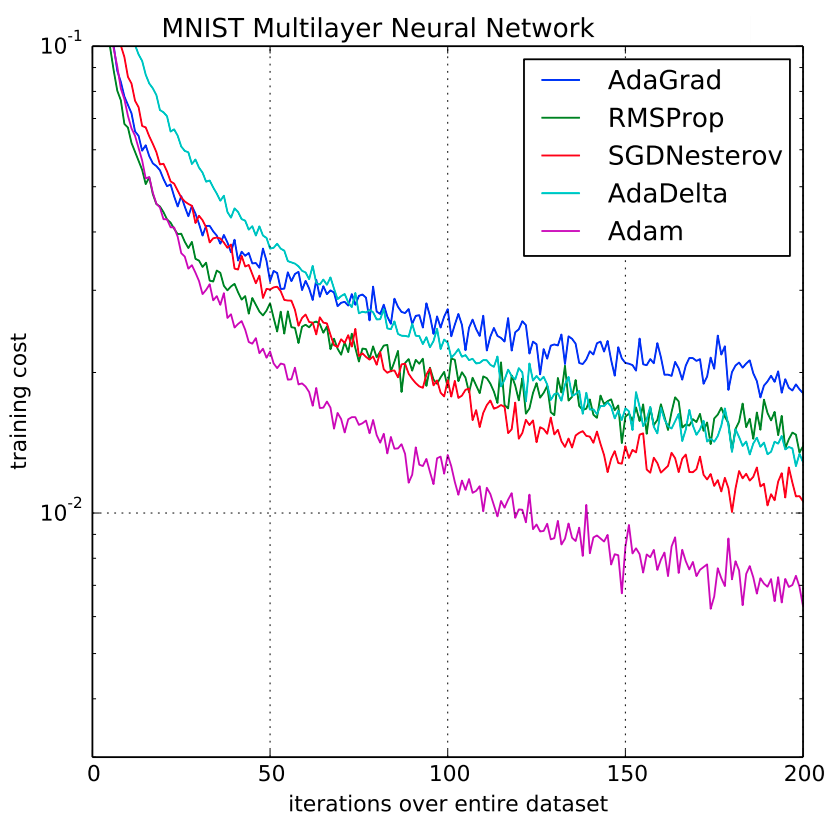
- Adam works better than other optimization methods
=>
- BUT, it requires setting ρ1, ρ2, η, and storing s and r
=> Memory demanding
Distributed Synchronous SGD
[ Computational Costs of Training Neural Network ]
- The cost depends on size of model, size of data, mini-batch size
- how many iterations/gradient (steps)
- Efficiency of optimization algorithm

- Spilt model across nodes, and process simultaneously with different mini-batch
(Parallelzing Deep Network Training)
- parameter server will wait to aggregate gradients from all the nodes,
then send new parameters
=> BUT, it requires to create central node
=> Bandwith needs to be high for synchronous SGD (need complex network-> cost increases)



