
Code&Data Insights
[Deep Learning] Convolutional Neural Network (CNN) 본문
[Deep Learning] Convolutional Neural Network (CNN)
paka_corn 2023. 11. 7. 02:00What is a Convolution?
: a standard operation, long used in compression, signal processing, computer vision, and image processing
Convolution = Filtering = Feature Extraction

Main difference with the MLP
1) Local Connection
: Local connections can capture local patterns better than fully-connected models
-> search for all the local patterns by sliding the same kernel
-> have the chance to react to patterns that are in different positions.
2) Weight Sharing
: differently to MLPs that employ different weights for different neurons
Kernel Size
: the wieghts of the filter w are learned from data
- the length of the convolving filter, the kernel size = k
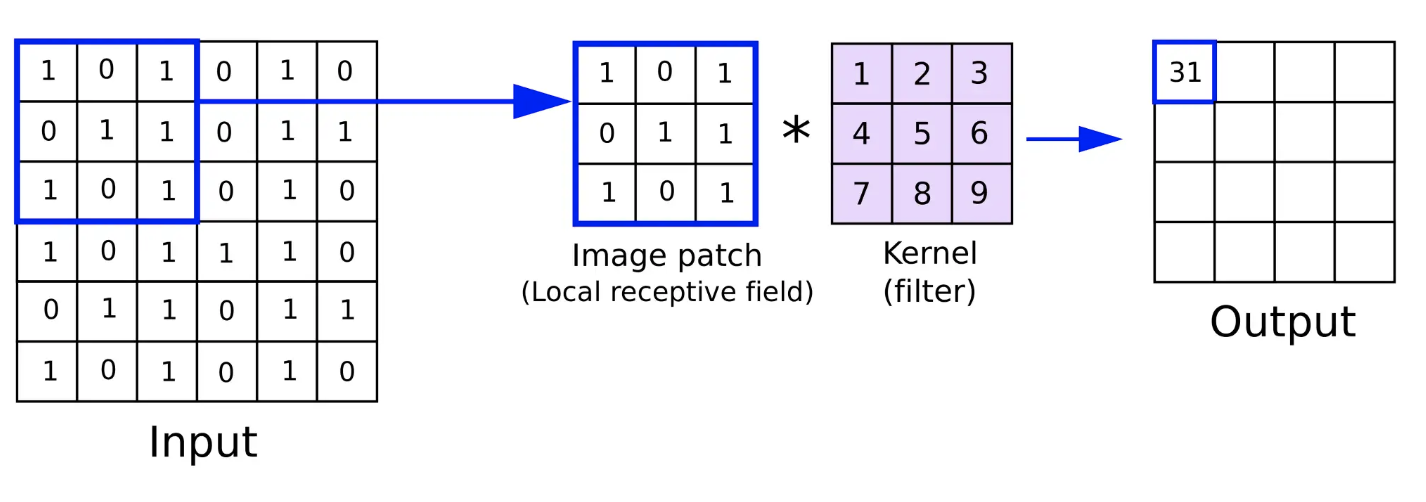
Input Channels
- In general, the convolution takes a multi-channel input, filters it with some filters, and returns multi-channel output
- The multi-channel input is processed by a filter of dimensionality
- The convolutional framework is flexible enough to manage multi-channel inputs as well.
multi channel input size = kernel_size * input channels
Output Channels
: the number of different feature maps generated through the convolution operation.
- Each output channel is responsible for detecting and storing various features.
- In CNN, we want each filter to react to different local patterns
- All these outputs produced by the convolution are gathered in single matrix with dimensionality
- To capture multiple patterns, we have to process the input with many different filters
-> Multiple output channels can be used by the model to learn more complex patterns.
Stride
: quantifies the amount of movement(step size) by which we slide a filter over an input
- hyperparameter of the convolution layer
- if stride facter is bigger than 1, the effect is to compress the input
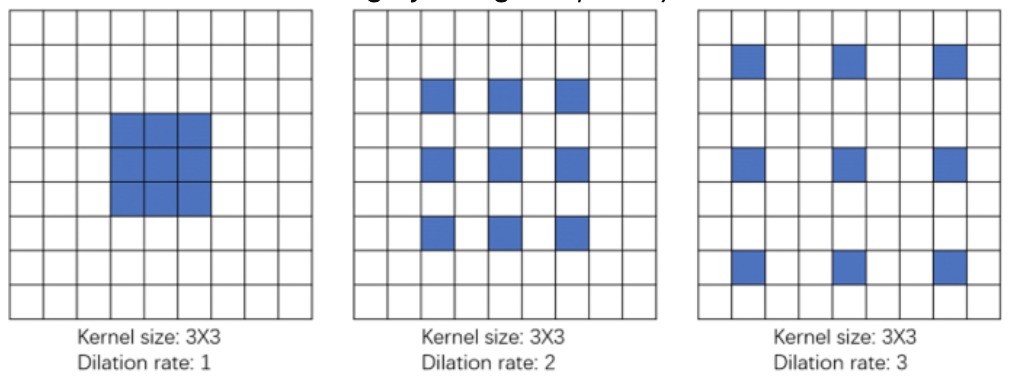
Dilated Convolution
- a technique that expands the filter by inserting holes between its consecutive elements
- can be done to cover a larger area of the input
Stacking Convolutional Layers
- we can stack multiple convolutional layers to form a deep convolutional network.
- optionally, normalization is applied right after the convolution (layernorm or batch norm)
- then, a non-linearity is applied (ReLU or LeakyReLU)
=> after non-linearity, the set of features = feature maps
- After stacking multiple convolutional layers, we can apply a final linear transformation(fully-connected layer)
- Finally, we apply a flattern operation that stacks in a single big vectore all the output channels
=> Feature Extraction
Receptive Field
: the region of the input space that affects a particular unit of the network

- Show what specific area of the input image a particular neuron is looking at.
- To put it simply, the receptive field of a neuron represents the area in the input that the neuron uses for its computations.
- Smaller receptive fields enable neurons to detect finer and more detailed features.
=> Therefore, in CNNs, the receptive field is a crucial concept that explains how the model perceives and understands various parts of an image.
* The receptive field depends on different factors
1) Kernel Size
2) Number of Layers
3) Stride Factor
4) Dilation factor
Parameters
- the number of paramters in 1D convolutional layer
=> kernel size x input channel x output channel
- the number of paramters in 2D convolutional layer
=> kernel size(x) x kernel size(y) x input channel x output channel
Pooling
: helps to make feature maps approximately invariant to small transitions of the input
- pooling is often applied after the non-liearity(activation function)
- the size of the sliding window and its stride factor are hyperparameters of the pooling operation
(ex) Max Pooling, Avg Pooling



