
목록Artificial Intelligence (67)
Code&Data Insights
 [Deep NLP] Attention | Transformer
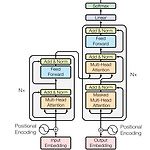
[Deep NLP] Attention | Transformer
Attention - Contextual embedding => Transform each input embedding into a contextual imbedding => Model learns attention weights - Self-attention : allows to enhance the embedding of an input word by including information about its context - Encoder-Decoder Attention : Attention between words in the input sequence and words in the output sequence => how words from two sequences influence each ot..
 [Deep NLP] Word Embeddings | Word2Vec
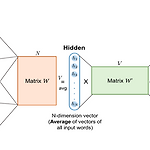
[Deep NLP] Word Embeddings | Word2Vec
Word Embeddings · Word Vectors - Simple approach : one-hot vectors => NOT represent word meanining => Similarity/distance between all one hot vectors is the same => Better approach : ‘Word Embeddings’! · Word2Vec : how likely is a word w likely to show up near another word? - Extract the learned weights as the word embeddings - Use as training set, readily available texts, no need for hand-label..
 [Statistical NLP] N-gram models
[Statistical NLP] N-gram models
N-gram models : a probability distribution over sequence of events · Models the order of the events · Used when the past sequence of events is a good indicator of the next event to occur in the sequence -> To predict the next event in a sequence of event · Allows to compute the probability of the next item in a sequence · Or the probability of a complete sequence · Applications of Language Model..
 [Statistical NLP] Bag of Word Model
[Statistical NLP] Bag of Word Model
Bag of Word Model - The order is ignored (in the sentence) - Fast/simple (ex) Multinomial Naïve Bayes text classification(spam filtering) Information Retrieval (google search) - Representation of a documents => Vectors of pairs => Word : all words in the vocabulary (aka term) => Value: a number associated with the word in the document - Different possible schemes (1) Boo..
 [Deep Learning] Recurrent Neural Networks (RNN)
[Deep Learning] Recurrent Neural Networks (RNN)
Recurrent Neural Networks (RNN) : the current output depends on all the previous inputs *SEQUENCE* Xt = current input Ht = previous state W = set of learnable parameters Comparison between a hidden RNN layer and a linear layer - Hidden RNN Layer : the memory that maintains info about past inputs in the sequence => The hidden state is updated at each time stop and can capture short-term dependenc..
 [Deep Learning] Regularization - Dropout | Data Augmentation | Multitask Learning
[Deep Learning] Regularization - Dropout | Data Augmentation | Multitask Learning
Regularization : techniques used to control the complexity of models and prevent overfitting are known as regularization techniques => Increase generalization ability! => Deep Neural Networks are models with large capacity and thus more prone to overfitting problems!!! Data Augmentation : create fake training data by applying some transformations to the original data - Used for classficiation pr..
 [Book] Hands On Machine Learning with Scikit Learn and TensorFlow - Chapter 2:End-to-End Machine Learning Project
[Book] Hands On Machine Learning with Scikit Learn and TensorFlow - Chapter 2:End-to-End Machine Learning Project
Main Steps in Machine Learning Project 1. Look at the big picture 2. Get the data 3. Discover and visualize the data to gain insights 4. Prepare the data for ML algorithms (data cleaning, preprocessing) 5. Select a model and train it 6. Fine-tune the model 7. Present your solution 8. Launch, monitor, and maintain your system 1. Look at the Big Picture - Frame the Problem(business objective) : wh..
 [Deep Learning] Convolutional Neural Network (CNN)
[Deep Learning] Convolutional Neural Network (CNN)
What is a Convolution? : a standard operation, long used in compression, signal processing, computer vision, and image processing Convolution = Filtering = Feature Extraction Main difference with the MLP 1) Local Connection : Local connections can capture local patterns better than fully-connected models -> search for all the local patterns by sliding the same kernel -> have the chance to react ..