
Code&Data Insights
[Deep Learning] Neural Networks - Perceptron | MLP | Activation Function | Backpropagation | Gradient Descent 본문
[Deep Learning] Neural Networks - Perceptron | MLP | Activation Function | Backpropagation | Gradient Descent
paka_corn 2023. 6. 22. 11:10Neural Networks
Neural Network : A neural network is composed of neurons that take inputs and calculate outputs through weights and activation functions. Through this process, it learns patterns in data and gains the ability to make predictions.
Learning in Neural Network
1) Feed Forward
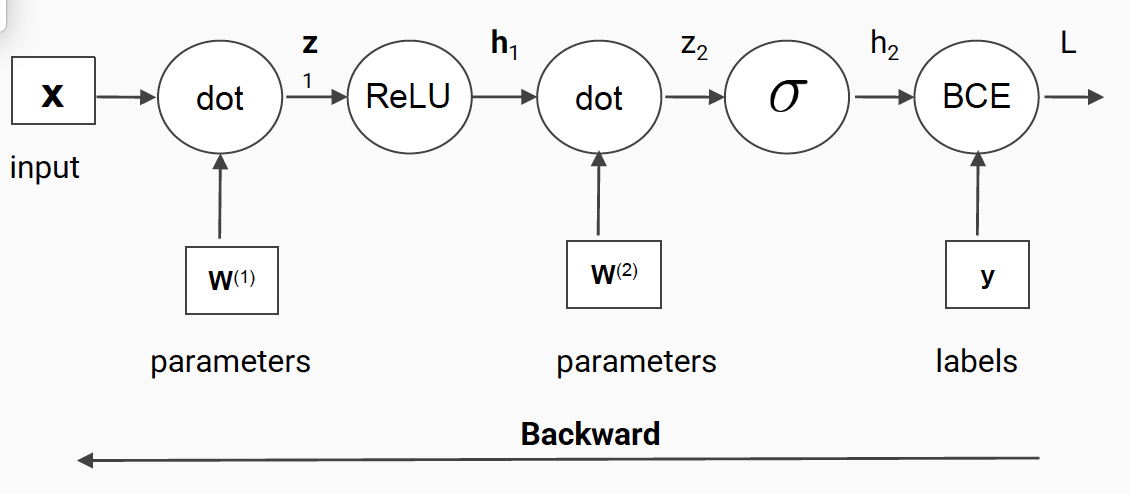
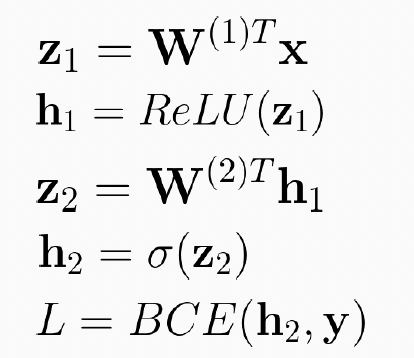
2) Compute Loss

3) Backpropagate ( = chain rule)
: the method to compute the gradient efficiently

4) Gradient Descent ( * Optimization Algorithm * )

: attempts to optimize the objective function by progressively updating the parameters (weights) using the gradient.
-> Find the best weight to minimize the loss!
Perceptron
Perceptron : A perceptron consists of one or more input nodes, weights assigned to each input, a summation function, an activation function, and an output node.

=> no hidden layer, only single layer
=> input nodes (features) + weights + output

- Sum(Weighted Sum) : decide how much weighted to be assigned to each feature.
: the sum of the inputs multiplied by their corresponding weights.
- Output : Apply activation function to Weighted Sum
- weight : learnable parameter, reflects the importance of the input.
- bias : an additional weighted input that is commonly added to each neuron, which serves as an offset that allows modifying the neuron’s output independently from the input
[ Limits of the Perceptron ]
- Can Only model linear decision boundaries
Multilayer Perceptron (MLP)


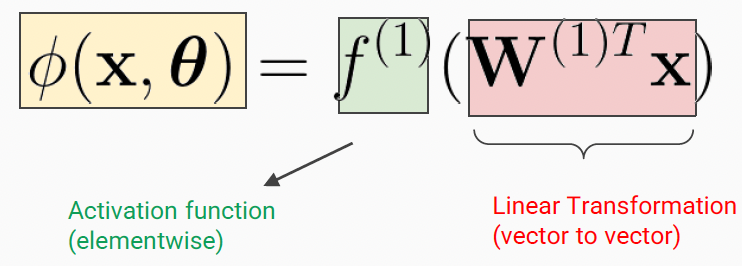
- each neuron performs a weighted sum of the previous inputs and then applies the non-linear activation function
- use a non-linear activation function for more complex decision boundaries
Activation Function
Activation Function : it generates outputs by receiving inputs from each neuron in an artificial neural network.
=> After computing the weighted sum of the input signals and bias, the activation function performs a non-linear transformation on the result to generate the output.

- the aim of introducing non-linearity to the neuron’s output, allowing for more complex representations.
1) Threshold Function

: if the value is less than 0, then 0
if value is more than 0, then 1.
-> Not used in real neural network.
=> If we use this function, adding more hidden layers doesn't work effectively; it behaves like a linear model.
2) Sigmoid Function

: the probability of the output to be equal to one.
- maps the input to a value between 0 and 1.
=> commonly used is to apply for the output layer (classification -> Yes or No)
* Due to the issue of vanishing gradient problem, activation functions like sigmoid and hyperbolic tangent are not commonly used in deep neural networks.
3) Rectifier Linear Unit (ReLU)

- maps negative inputs to 0, and maintains positive inputs
=> commonly used is to apply for the hidden layer
4) Leaky ReLU
: allows a small, non-zero gradient when the input is negative, preventing the vanishing problem in ReLU function.

5) Hyperbolic Tangent(tanh)
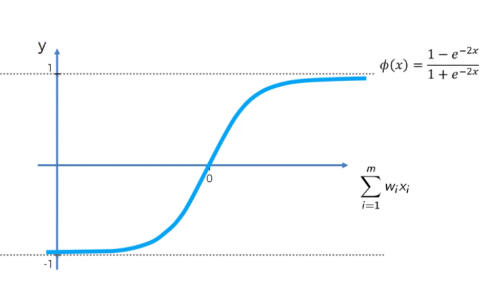
: similar as sigmoid function, but the range is from -1 to 1.
- generates a probability distribution across the possible outputs (usually for discrete outputs), where the sum of the probabilities adds up to 1.
- commonly used at the output layer for classification tasks.
* Due to the issue of vanishing gradient problem, activation functions like sigmoid and hyperbolic tangent are not commonly used in deep neural networks.
Backpropagation
: backpropagation is the algorithm which calculates the gradient of the error function with respect to the neural network's weights
applying the chain rule of calculus to compute the partial derivatives of the error with respect to the weights.
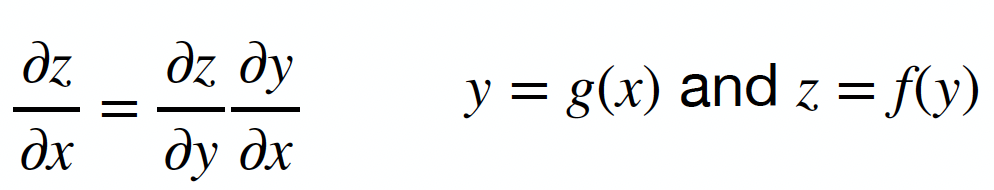
the weights of the network are then updated using an optimization algorithm (commonly gradient descent) in a direction that reduces the error.

Gradient Descent
Gradient Descent
=> find the minimum cost function by derivation
cost function = 1/2(y(hat) - y)^2 = 1/2(prediction value - actual value)^2
Cost Function (=Lost function) = RSS (Residual Sum of Square)


==> Backpropagation vs Gradient descent
backpropagation : compute gradient!
gradient descent : optimization algorithm to find the gradient to minimize the error!!!



