
목록All Contents (172)
Code&Data Insights
해외사이트 - https://techcrunch.com/category/artificial-intelligence/ AI News & Artificial Intelligence | TechCrunch Read the latest on artificial intelligence and machine learning tech, the companies that are building them, and the ethical issues AI raises today. techcrunch.com - https://thegradient.pub/ The Gradient A digital publication about artificial intelligence and the future. thegradient.pub..
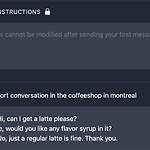 [Generative AI] Generate Text using Generative AI (ChatGPT-3.5)
[Generative AI] Generate Text using Generative AI (ChatGPT-3.5)
WITHOUT PROMPT => Prompt Instruction 없이 매우 평범하고 짧은 대화가 생성됨 WITH 1st PROMPT => 처음 대화보다 좀 더 친근한 버전이지만, 실생활에서 다른 대화 없이 주문을 받고 난 뒤 우리 커피샵을 골라줘서 고마워 이렇게 말하는 것은 어색하다고 생각함. WITH 2nd PROMPT => 원래 의도는 손님이 원하지 않는 경우에도 베이커리 메뉴 추천을 해서 수익을 올리려는 목적인데, 애초에 생성된 대화 내용이 손님이 추천을 원하는 경우로 나왔다. WITH 3rd PROMPT : 같은 prompt instruction이지만, prompt를 상세하게 설정(손님이 커피만 시키고 싶어하는 경우) => 의도한 결과와 실제상황과 가까운 자연스러운 대화가 생성됨!
Generative AI : 트레이닝 데이터를 기반으로 다양한 포맷(text, images, code, audio, video)의 새로운 컨텐츠를 생성해주는 AI 모델. Generative AI models are trained on substantial datasets of existing content and learn to generate new content similar to the data they were trained on. - Generative AI can start from the prompt, prompt can be Text/ Image/ Video/etc and then, it generates a new content as text/images/audio/video/code/d..
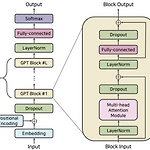 [NLP] Large Language Model (LLM)
[NLP] Large Language Model (LLM)
Large Language Model (LLM) : 자연어 처리를 위해 방대한 양의 데이터로 학습된 인공지능 모델로 인간과 유사한 텍스트를 처리, 이해 및 생성하도록 설계된 고급 AI 시스템. A type of deep learning model trained on massive amounts of text data to learn the patterns and structures of language. They can perform language-related tasks, including text generation, translation, summarization, sentiment analysis, and more. - LLMs work by training on diverse language ..
 [Prompt Engineering] AI hallucinations
[Prompt Engineering] AI hallucinations
AI hallucinations이란 ? : AI models이 생성한 incorrect하거나 misleading results. - 트레이닝 데이터가 충분하지 않거나 잘못된 가정, 데이터의 편향으로 인해 잘못된 패턴을 습득하여 잘못된 예측, hallucinations이 발생! - 특히, 의학적 진단, 금융 거래는 정확한 결과가 중요함! ==> hallucinations을 예방하거나 줄이고 정확한 결과를 얻기 위해 프롬프트 엔지니어링은 빠르고 쉬운 방법이 될 수 있다. AI hallucinations 왜 발생하는 가? (1) 생성 모델의 한계 : 생성적 AI 모델은 훈련 데이터에 기반하여 알고리즘적으로 작동함. - 관찰된 패턴을 기반으로 다음 단어나 시퀀스를 예측하는 것이 목표. - 진실을 검증하는 것에 ..
Zero-Shot Learning : 예시 없이 그냥 Prompt 입력 (one-shot learning : 하나의 예시만 제공) Zero-Shot Prompting : A method wherein models generate meaningful responses to prompts without prior training (ex) prompt : select the adjective in this sentence "Anita bakes the best cakes in the neighborhood." - output : "Best" => HOWEVER, 1-prompt로 desired output(원하는 결과)를 얻기는 힘듬!! User Feedback Loop : 계속되는 prompt(by user..
What Is Prompt Engineering? 프롬프트 엔지니어링은 AI 모델, 특히 LLM을 원하는 결과로 유도하기 위해 정교하게 설계된 질문이나 지시를 만드는 과정. 원하는 결과물을 얻기 위해 프롬프트를 최적화하는 기술 Prompt engineering is essential for enhancing AI-powered services and maximizing the output of existing generative AI tools. Powerful prompts lead to => Optimize the response of generative AI models => Power lies in the questions we ask => Write a prompt that is effectiv..
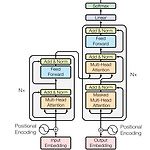 [Deep NLP] Attention | Transformer
[Deep NLP] Attention | Transformer
Attention - Contextual embedding => Transform each input embedding into a contextual imbedding => Model learns attention weights - Self-attention : allows to enhance the embedding of an input word by including information about its context - Encoder-Decoder Attention : Attention between words in the input sequence and words in the output sequence => how words from two sequences influence each ot..