
Code&Data Insights
[Machine Learning] Regularization - Early Stopping | Weight Decay | Dropout 본문
[Machine Learning] Regularization - Early Stopping | Weight Decay | Dropout
paka_corn 2023. 11. 6. 00:42Regularization
: prevent overfitting and improve the generalization of a model
- It introduces additional constraints or penalties into the model training process to discourage the model from becoming too complex.
- It aims to strike a balance between fitting the training data well and maintaining simplicity in the model
Early Stopping
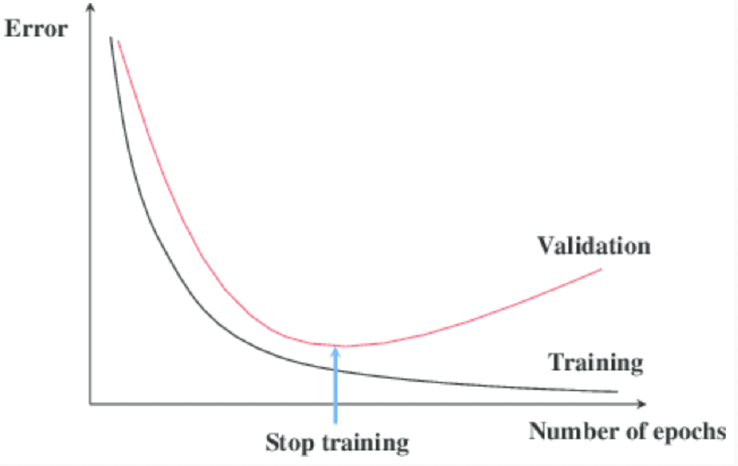
: monitor the performance after each epoch on the validation set and stop training if the validation performance starts to get worse.
When Overfitting Happens?
- too many parameters,
- less training dataset
How to Avoid Overfitting?
- Improve Generalization!
1. Weight Decay
: Limits the size of weights (model parameters) and prefers smaller weights, thereby reducing the complexity of the model
· Why we use weight decay?
: to avoid overfitting
· When it is useful
- Limited training data
=> Small dataset has higher risk of the model memorization
- Complex model (multidimensional)
=> higher capacity to fit the training data perfectly can lead to overfitting
- Many parameters
=> More parameters can make the model more prone to overfitting
=> It reduces the influence of individual parameters.
L2 Ridge
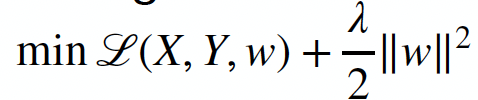
L2 regularization(Ridge regularization)
- The regularization term penalizes large weights
- it encourages the model to have small weights.
- The strength of this penalty is controlled by a hyperparameter commonly denoted as "λ" (lambda).
- A higher λ value leads to a stronger regularization effect, pushing the weights closer to zero.
Weight decay for vanilla SGD corresponds to an L2 regularization
2. Dropout
: only mask training set, NOT test set
- useful in small dataset
Dropout : a regularization technique used in neural networks and deep learning to prevent overfitting.
· During training,
- Dropout operates by randomly deactivating connections of selected neurons (nodes). => if the dropout probability is 0.5, each neuron has a 50% chance of being deactivated.
- This random deactivation encourages the model to learn various weight combinations, preventing overfitting and enhancing generalization.
· During testing,
- all neurons are activated. In other words, Dropout is deactivated, and all weights are utilized



