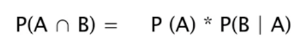Code&Data Insights
[Machine Learning] Classification - K-Nearest Neighbours(KNN) | Naive Bayes 본문
[Machine Learning] Classification - K-Nearest Neighbours(KNN) | Naive Bayes
paka_corn 2023. 6. 16. 09:00[ K-Nearest Neighbours ]
K Nearest Neighbors (KNN)
=> KNN is a supervised learning classifier, which uses proximity to make classifications or predictions about the grouping of an individual data point.

How It Works?
Step 1)
Choose the number K of neighbors
Step 2)
Take the K nearst neighbors of the new data point, according to the Euclidean distance
- Euclidean Distance : √((x₂ - x₁)² + (y₂ - y₁)²) | P1(x₁,y₂) , P2(x₂,y₂)
Step 3)
Among these k neighbors count the number of data points in each category
Step 4)
Assign the new data point to the category where you counted the most neighbors
=> After 4-step, the model is ready!
[ Naive Bayes ]
Naive Bayes : Naive Bayes is naive because it treats all word orders the same.
- In Naive Bayes, all features(variables) are independent!
-> Used in Text Classification, Spam Filtering


Conditional Probability
Conditional Probability - two event A and B are independent

Conditional Probability - two event A and B are dependent