
Code&Data Insights
[Machine Learning] Bias and Variance | Regularization | Learning Curves 본문
[Machine Learning] Bias and Variance | Regularization | Learning Curves
paka_corn 2023. 5. 31. 05:07[ Bias ]
Bias - the inability for machine learning method to capture the true relationship

-> In linear regression, the straight line has high bias. (underfit)
-> Compared to the Squiggly line, it has low variance since the sums of squares are very similar for different data set.

[ Variance ]
Variance : the difference in fits between data sets.

It has very little bias, but high variance !
--> fits the training set exetremely well ! => Overfit | High Variance
( Overfit : works perfectly with the training set(given dataset), but it does not work well with new examples that are not in the training set )
( High variance : the model is too dependent with the train_data, therefore the prediction with the new data will be unstable and not correct! )
-> The squiggly line has low bias since it can be match with the training set
-> However it has high variance, so the sums of squares are very dissimilar for different data set.
=> It's hard to predict with the future data set
To reduce overfitting?
- Collect more training set
- Lower the variance
- feature selection : select features to include/exclude ( disadvantage : could lost useful features )
- Use Regulization !
[ Ideal ML Algorithm ]
Ideal ML Algorithm - has low bias & low variability(variance)
-> low bias = can accurately model the true relationship
-> low variability(variance) = produce consistent predictions across different dataset

fits the training set pretty well. => generalization !
===> nor underfit or overfit
===> low bias & low variability(variance)
Three commonly used methods for finding Ideal ML Algorithm
1) Regularization
2) Boosting
3) Bagging
[ Regularization ]
Regularization : reduce the size of parameter w



- If lambda = 0, it is overfit
- If lambda is too large, it is underfit since f(x) = b!
Increasing the reduces overfitting by reducing the size of the parameters.
=> For some parameters that are near zero, this reduces the effect of the associated features.

** we don't have to regularize b !
For regularized **logistic** regression, how do the gradient descent update steps compare to the steps for linear regression?
=> They look very similar, but the is not the same.
==> For logistic regression, is the sigmoid (logistic) function, whereas for linear regression, is a linear function.
[ Learning Curves (= Learning Algorithm) ]
Learning algorithm (= learning curves) : a way to help understand how your learning algorithm is doing as a function of the amount of experience it has.
If a leaning algorithm suffers from high bias, getting more training data wil not help much!
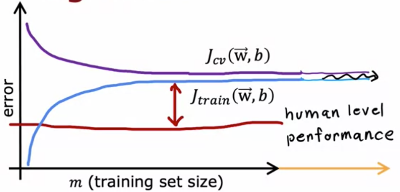
If a leaning algorithm suffers from high variance, getting more training data will help much!
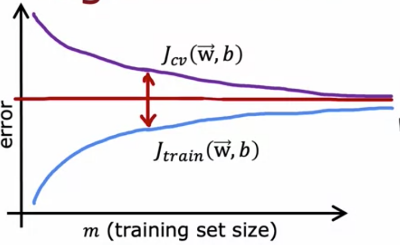
Debugging a learning Algorithm
To fix high bias
1) Try getting additional features
2) Try adding polynomial features
3) Try decreasing lambda
To fix high variance
1) gets more training examples
2) try smaller sets of features
3) try increasing lambda

